Home
Data
Data is the primary informational component in this era of Artificial Intelligence and Big Data. The need for more and more data has been arising tremendously in the last decade, and the massive data explosion has resulted in the culmination of new analytical technologies. Thus, Data Science has emerged as an inter-disciplinary field that uses scientific methods to extract knowledge and insights from many structural and unstructured data. The ability of analysing and uncovering hidden patterns, correlations and other insights from large amounts of data is a fundamental skill in order unlock the evidences and answers that can makes a competitive difference.
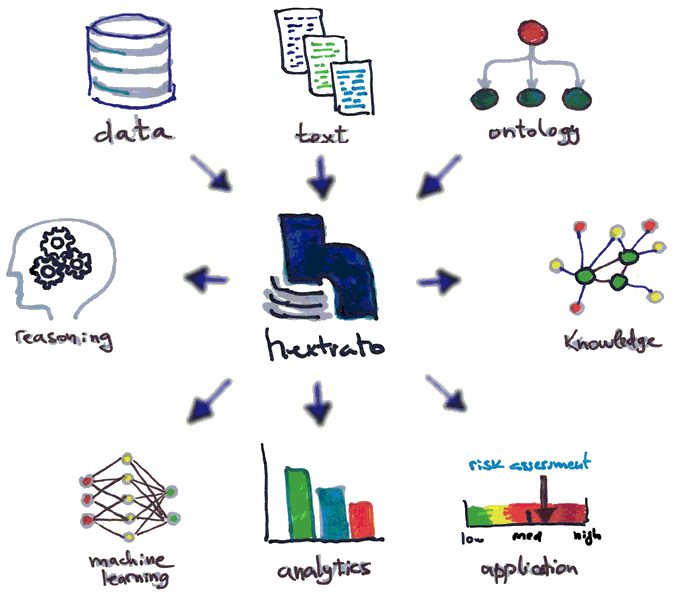
hextrato has been initially designed to be an analytical tool based on structured data from relational databases. However, it has been evolving to incorporate other knowledge-based technologies such as ontologies, knowledge graphs, embedding representation, machine learning and analytical tools, enabling the development of more sophisticated use-cases.
Text
The increasing amount of textual data either being produced by different kinds of information systems or being published on Internet, requires specific analytical tools in order to provide substantial competitive advantages within the era of a knowledge-based economy.
The increased interest in finding and sorting information from text documents allowed the development of text mining techniques for extracting non-trivial knowledge from unstructured documents, such as using the principles of computational linguistics to find associations and non-trivial patterns from textual documents.
Text analysis includes extracting information using algorithms to understand and recognise the knowledge contained in the text, enabling applications such as question answering and information retrieval systems to offer more precise answers, which imposes multiple problems and challenges, including but not limited to:
a) how to identify strings representing the subjects in sentences
b) how to disambiguate entities and events, and assign them to the appropriate semantic classes
c) how to extract the values for the various attributes from the text
d) how to connect events to a timeline
Ontology
Ontologies are formal specifications of conceptualizations, and are increasingly being used, and considerably growing in number, complexity and domains they model, playing an important role in resolving semantic heterogeneity. Their designs require to understand the concepts involved in the target domain, including entities and categories in a subject area or domain that shows their properties and the relations between them.
Ontology = ontos (being) + logos (science, study)
Besides defining a common vocabulary that enables sharing information in a domain, ontologies include a set of machine-interpretable definitions in the domain and relations among them, that can be used to:
a) make domain assumptions explicit
b) enable reuse of domain knowledge
c) enable knowledge inference and reasoning
Reasoning
Reasoning means deriving facts that are not expressed in ontology or in knowledge base explicitly. The use of the term ontology in computer science is related to building knowledge bases using automatic computational reasoning, with interoperable structures that describe concepts and relations among them.
Reasoners can also be used through the inference of logical consequences, allowing the evaluation of the generated knowledge bases, by contrasting the ontological definitions against the output data complied after the execution of the mapping rules. See the very simple example below:
Assertion:
Fluoxetine is_a AntidepressantDrug
Rule:
has_been_prescribed isEquivalentTo is_under_treatment_of
Fact:
Patient#1 has_been_prescribed Fluoxetine
Inferred:
Patient#1 is_under_treatment_of AntidepressantDrug
Knowledge Bases
Information Extraction enables the extraction of facts from large quantities of heterogeneous data, attempting to capture that information using a multi-relational representation. Knowledge Graphs are a multi-relational datasets composed by entities (nodes) and relations (edges) that provide a structured representation of the knowledge about the world, in which each entity represents one of various types of an abstract concept or concrete entity of the world (e.g. people, companies, countries, songs, diseases, drugs) and each relation is a predicate that represents a fact involving two entities.
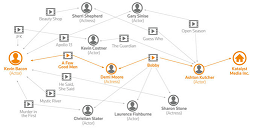
Within the clinical domain, knowledge graphs can be used to represent patient encoded in the form of triples. Information from Electronic Health Record (EHR) systems can easily be used to capture a multi-relational representation that connects structured and heterogeneous information, providing quantitative variables for statistical analysis, and the ability to tackle problems from a relationship perspective.
Embedding Representation
Knowledge embedding methods can efficiently measure semantic correlations in knowledge bases by projecting entities and relations into a dense low-dimensional space, significantly improving performance on knowledge inference and alleviating sparsity issues. Thus, learning the distributed representation of multi-relational data can be used as a tool to find similar entities that share similar features.

When learning embedding representation for domain-specific data, such as patient information in the clinical domain, independent hyperspaces can be used to acommodate each specific category of entities, thus giving more space to alliviate competition between entities from multiple types. This has been proven to be more efficient to guarantee embedding quality than tradicional embedding approaches from usually evaluated using open-domain benchmark datasets.
Embedding Scoring
Embedding methods can be evaluated based on multiple metrics for each given target label, such as clustering, AUPRC/AUROC, and F-scores. Thus each subset of features can potentially provide a good predictor for a subsequent assessment task.
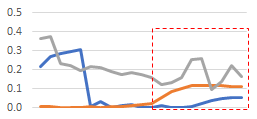
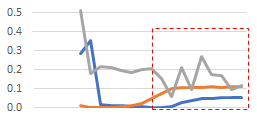
In this examples two subsets of features show the thresholds (x axis) when the F1-score (orange) starts to increase and the corresponding support (blue) and AUPRC (gray).
The scoring evaluation is performed by injecting synthetic instances that carry risk scores for each specific target label based on a representative subset of feature values. Embedding scoring then helps on defining the thresholds that are more consistent to perform individual prediction when resulting embeddings are submitted to subsequent assessment tasks.
Neural Networks
Data Science has been built on the discovery, interpretation, and communication of meaningful patterns in data, which entails applying such resultinng data patterns towards supporting more effective decision making processes.
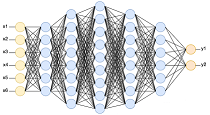

We have been investigating how to use knowledge embedding representation and their corresponding label-centric scoring metrics as input of neural networks in order to effectively boost performance on subsequent deep learning tasks, aiming to provide consistent outputs to support decision making, such as patient classification and risk score assessment within the clinical domain.
Data Analytics
Business Intelligence systems are well-known as providing strategies and technologies for historical and predictive data analysis. However, their methodologies, processes, architectures, and technologies require to be reviewed in this new era of deep learning and multi-modal data
Having nice colored dashborads is now far from being enough to support decision making, as new fatures are required to be incorporated wihtin analytical tools in order to transform raw data into meaningful and useful information to enable more effective strategic, tactical, and operational insights and decision-making:") )
a) respond to natural language queries
b) incorporate textual sources
c) deal with uncertainty and imprecision
d) provide analysis trackability and explainability
Application
We aim to combine knowledge representation, embedding scoring metrics, and machine learnng approaches to deliver risk assessment application in the clinical domain. Thus, we are looking at the problem of how to model EHR (electronic Health Record) data into an efficient embedding representation that can be used in subsequent machine learning tasks.